In the fast world of ride-sharing, Uber stands out because of its large network, easy-to-use app, and smart dynamic pricing, known as “surge pricing.” This system changes ride prices based on real-time demand and supply, making sure riders can get a car when they need one and drivers are paid fairly. At the core of this real-time pricing system is Apache Kafka, a powerful tool for handling large amounts of data quickly. In this blog, we will explore how Uber uses Kafka to power its dynamic pricing model.
Table of Contents
The Need for Dynamic Pricing
Dynamic pricing is essential for Uber to maintain an equilibrium between ride demand and driver supply. During peak times, such as rush hours, concerts, or adverse weather conditions, demand for rides can significantly outstrip the available supply of drivers. If prices remain static, riders may experience long wait times, or worse, find no available rides. Conversely, during off-peak times, without dynamic pricing, drivers might not find it worthwhile to stay available, leading to a shortage when demand does spike again.
Dynamic pricing addresses these challenges by:
- Balancing Supply and Demand: By increasing prices during high demand, Uber incentivizes more drivers to come online and serve the market.
- Ensuring Availability: Higher prices discourage some riders from booking immediately, reducing demand to match the available supply.
- Fair Compensation: Drivers receive higher earnings during peak times, making their time and effort worthwhile.
Apache Kafka: The Backbone of Uber’s Pricing Engine
Uber’s dynamic pricing relies heavily on real-time data processing. This is where Apache Kafka comes into play. Kafka’s ability to handle high-throughput, low-latency data streams makes it ideal for Uber’s requirements. Let’s delve into how Kafka fits into Uber’s architecture and supports the dynamic pricing model.
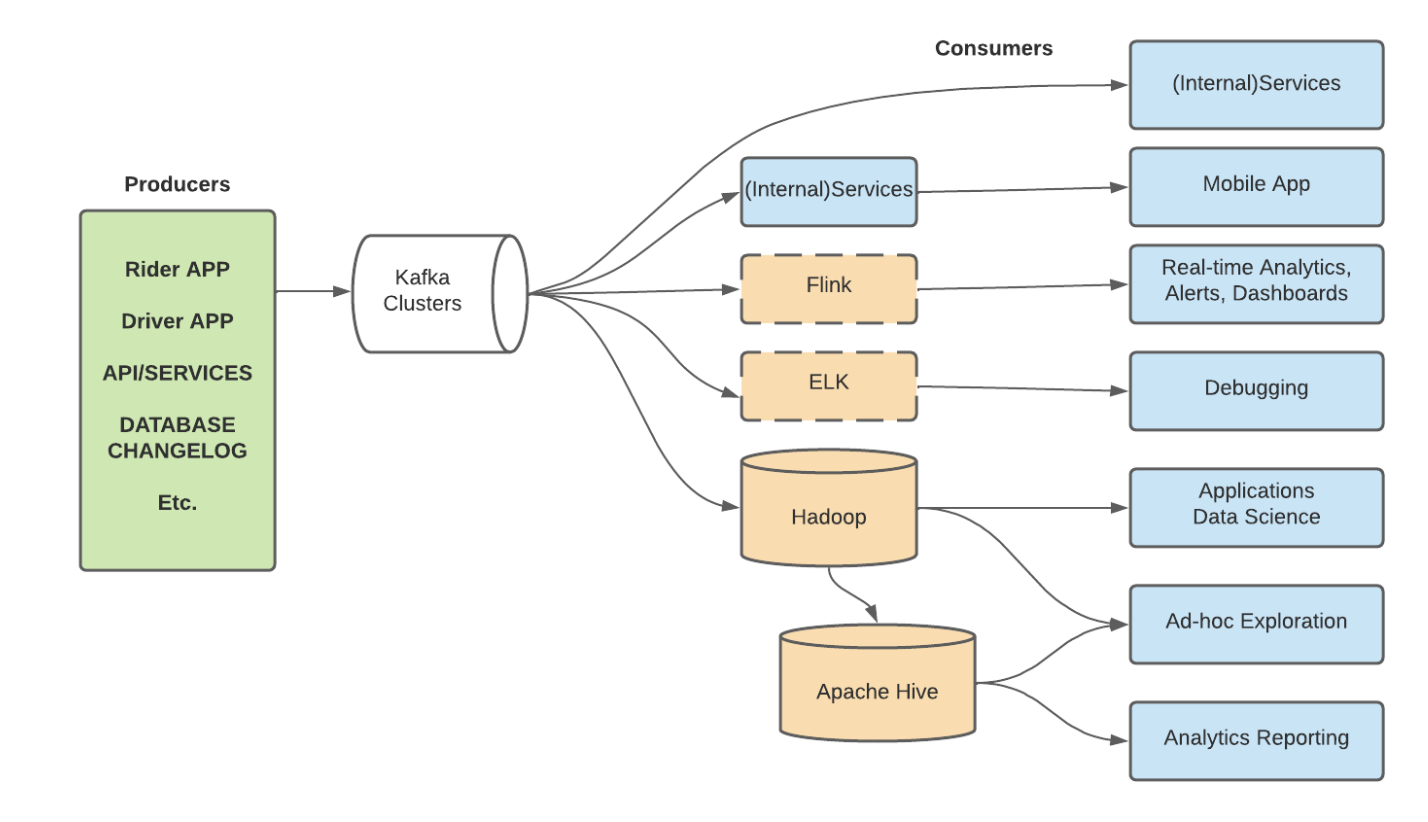
Data Producers
The dynamic pricing model starts with data collection from various sources, known as producers in Kafka terminology. These include:
- Rider App: Provides data on ride requests, user location, ride preferences, and payment information.
- Driver App: Sends data about driver availability, location, status (e.g., available, on a ride, offline), and earnings.
- API/Services: Collects data from different Uber services such as trip completions, cancellations, and fare calculations.
- Database Changelog: Captures changes in the database, such as new user registrations, updates to driver status, or changes in fare policies.
- Other Sources: Includes external data such as traffic conditions, weather updates, and events that could impact ride demand.
These producers generate vast amounts of data continuously, which Kafka ingests and stores efficiently.
Kafka Clusters
Kafka clusters act as the central hub for all the data streams from the producers. Kafka is designed to handle high throughput, making it capable of ingesting millions of data points per second. Its architecture allows for scalable data storage and retrieval, ensuring that data is available in real-time for processing.
Key features of Kafka that benefit Uber include:
- Scalability: Kafka can scale horizontally by adding more brokers to handle increased load.
- Durability: Kafka persists data on disk, ensuring it is not lost even if some components fail.
- High Throughput: Kafka’s design allows for handling large volumes of data with minimal latency.
- Partitioning and Replication: Kafka’s partitioning and replication ensure data is distributed and duplicated across multiple nodes, providing fault tolerance and high availability.
Data Consumers
Once the data is ingested by Kafka, it needs to be processed and utilized by various consumers. At Uber, the primary consumers include:
- Internal Services
- Internal APIs and Microservices: These services consume data directly from Kafka to keep Uber’s backend systems synchronized. They ensure that the latest information about ride requests, driver availability, and pricing conditions is accessible across the platform.
- Mobile Apps: Both the rider and driver apps need real-time updates. For riders, this means accurate wait times and pricing information. For drivers, it means up-to-date information on ride requests and earnings.
- Real-Time Data Processing
- Apache Flink: Flink is used for real-time data analytics, generating alerts, and updating dashboards. It processes stream data to provide immediate insights and trigger actions based on predefined rules. For example, if the number of ride requests in a particular area spikes suddenly, Flink can trigger an alert to adjust the pricing in that area.
- Real-Time Analytics, Alerts, and Dashboards: These tools provide insights into current system performance, helping Uber manage demand fluctuations and ensure that dynamic pricing adjusts as needed.
- Log Analysis and Debugging
- ELK Stack (Elasticsearch, Logstash, Kibana): This stack is used for logging and debugging. Elasticsearch indexes the logs, Logstash processes them, and Kibana provides visualization. This setup helps Uber’s engineering teams monitor system performance and troubleshoot issues in real-time, ensuring the platform remains reliable and responsive.
- Big Data Storage and Batch Processing
- Hadoop: Hadoop is used for large-scale data storage and batch processing. It stores historical data which can be analyzed to identify trends and patterns over time.
- Apache Hive: Built on top of Hadoop, Hive provides a data warehouse infrastructure. It allows analysts and data scientists to perform ad-hoc exploration and querying of large datasets. They can generate reports and derive insights that inform Uber’s long-term strategies.
- Applications in Data Science: Data scientists use Hadoop and Hive to build predictive models, which can forecast demand and optimize pricing strategies. These models help ensure that dynamic pricing is not just reactive but also proactive, anticipating changes in demand.
Use Case: Real-Time Surge Pricing
To understand how Kafka supports real-time surge pricing, let’s walk through a typical scenario:
- Data Collection: As soon as a rider opens the app and requests a ride, data about the request is sent to Kafka. Simultaneously, data from drivers in the area, including their availability and location, is also sent to Kafka.
- Data Ingestion: Kafka ingests this data in real-time and makes it available to various consumers.
- Processing with Flink: Apache Flink processes the incoming data streams to identify patterns, such as an unusually high number of ride requests in a specific area.
- Triggering Surge Pricing: Based on the analysis, if demand significantly exceeds supply, Flink triggers an alert to adjust the pricing. This information is immediately sent back to Kafka.
- Updating Mobile Apps: The updated pricing is then consumed by the internal services responsible for the rider and driver apps. Riders see the new surge price, and drivers are notified of increased earnings potential in high-demand areas.
- Continuous Monitoring: The system continuously monitors the data to ensure that prices remain optimal as conditions change. If more drivers enter the high-demand area and balance the supply-demand ratio, the surge pricing is reduced or removed.
The Benefits of Using Kafka in Uber’s Pricing Model
- Real-Time Processing: Kafka’s low-latency data processing ensures that Uber can make pricing decisions in real-time, which is critical for maintaining a responsive and reliable service.
- Scalability: Kafka’s ability to scale horizontally allows Uber to handle increasing data volumes as the platform grows.
- Reliability: Kafka’s architecture, with features like data replication and fault tolerance, ensures that data is not lost and the system remains operational even in case of failures.
- Flexibility: Kafka’s support for various consumers allows Uber to integrate multiple processing tools like Flink, ELK, Hadoop, and Hive, each serving different purposes but all contributing to the overall goal of efficient data processing and utilization.
Conclusion
Uber’s dynamic pricing model is a testament to the power of real-time data processing. By leveraging Apache Kafka, Uber can efficiently handle vast amounts of data from multiple sources, process it in real-time, and make informed pricing decisions that balance supply and demand. This not only ensures that riders can get a ride when they need one, but also that drivers are compensated fairly, ultimately enhancing the overall user experience.
As Uber continues to grow and evolve, the role of Kafka in its pricing model will likely become even more significant, supporting new features and optimizations that further refine the dynamic pricing engine. For businesses looking to implement similar real-time data processing capabilities, Uber’s use of Kafka provides a compelling case study in the power and flexibility of this robust streaming platform.
Read also Apache Airflow Vs Apache NiFi.



