Have you ever wondered why we don’t use Apache Airflow to process data directly? Why is it necessary to integrate Apache Spark with Apache Airflow? Take a moment to think about the answer, and then check out this Don’t Use Apache Airflow in That Way to find out why don’t use Apache Airflow to process data directly. And come back to know How to run Spark jobs using Apache Airflow.
Apache Spark is a powerful open-source big data processing framework that allows users to process large amounts of data in a distributed manner. Check this Apache Airflow Tutorial for more information. Airflow is an open-source platform used to programmatically author, schedule, and monitor workflows. By combining Apache Spark with Airflow, users can easily create and manage complex data processing pipelines that can scale to handle large amounts of data. If you want to know the steps for running Apache Airflow check this How to Run Apache Airflow Locally.
In this article, we will discuss how to execute Apache Spark jobs using Airflow. We will cover the basics of Airflow and Apache Spark, how to configure Airflow to run Spark jobs, and how to create and schedule Spark jobs using Airflow. We will also provide some best practices and tips for optimizing and troubleshooting Spark jobs in Airflow. By the end of this article, readers should have a good understanding of how to use Airflow to orchestrate and manage Apache Spark jobs.
Table of Contents
Steps for Automate Spark Job Using Apache Airflow:
1- Import the library
To begin, the first step is to import the appropriate library for Apache Spark.
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator2- The parameters for the SparkSubmitOperator:
It is important to understand the parameters SparkSubmitOperator so that the Spark configuration can be tuned for optimal efficiency. Here’s a detailed explanation of the parameters for the SparkSubmitOperator:
task_id: A unique identifier for the task, used to reference the task within the DAG.application: The path to the application or script that contains the Spark job to be executed. This can be a local file or a file on a distributed file system like HDFS.conn_id: The ID of the connection to the Spark cluster. This connection must be defined in Airflow’s connections, which can be accessed via the Airflow UI.conf: A dictionary of configuration properties to be passed to the Spark job. These properties can be used to configure the Spark job itself, such as setting the number of executors or memory allocation.files: A list of files to be uploaded and distributed to the Spark cluster when the job is executed. These files can be referenced by the Spark job using their local paths.py_files: A list of Python files to be uploaded and distributed to the Spark cluster when the job is executed. These files must be importable by the Spark job and can be used to provide additional functionality or libraries.archives: A list of archives to be uploaded and extracted to the Spark cluster when the job is executed. These archives can be used to provide additional dependencies to the Spark job.driver_memory: The amount of memory to allocate to the Spark driver when it runs. This parameter is used to set thespark.driver.memoryconfiguration property.executor_memory: The amount of memory to allocate to each Spark executor when they run. This parameter is used to set thespark.executor.memoryconfiguration property.executor_cores: The number of CPU cores to allocate to each Spark executor when they run. This parameter is used to set thespark.executor.coresconfiguration property.num_executors: The number of executors to allocate for the Spark job. This parameter is used to set thespark.executor.instancesconfiguration property.name: The name of the Spark job. This parameter is used to set thespark.app.nameconfiguration property.verbose: Whether or not to print the Spark job logs to the console. If set toTrue, the logs will be printed to the console as the job runs. If set toFalse, the logs will only be available in the Airflow UI.
3- Define the SparkSubmitOperator Task:
Let’s begin by defining the necessary parameters for the SparkSubmitOperator task.
with DAG("AY_data_pipleine",start_date=datetime(2023,5,27),
schedule_interval="@daily",default_args=default_args, catchup=False) as dag:
run_spark_job = SparkSubmitOperator(
task_id = "run_spark_job",
application = "/opt/airflow/dags/scripts/forex_processing.py",
conn_id = "spark_conn",
verbose = False
)This code creates a DAG (Directed Acyclic Graph) in Apache Airflow that schedules and runs a Spark job using the SparkSubmitOperator.
The DAG is created with the following parameters:
AY_data_pipleine: the name of the DAG.start_date=datetime(2023,5,27): the start date of the DAG.schedule_interval="@daily": the interval at which the DAG should be run, in this case, daily.default_args=default_args: any additional default arguments for the DAG.catchup=False: whether or not to run backfill for the DAG.
The SparkSubmitOperator is a task within the DAG that runs a Spark job with the following parameters:
task_id = "run_spark_job": the name of the task.application = "/opt/airflow/dags/scripts/forex_processing.py": the path to the Python script containing the Spark job.conn_id = "spark_conn": the connection ID for the Spark cluster.verbose = False: whether or not to print the Spark job logs to the console.
4- Create a Connection between Spark and Apache Airflow
We want to Add a new record for the Spark connection in the Airflow connection is an important step because it allows the Airflow DAG to connect to the Spark. The steps are given below.
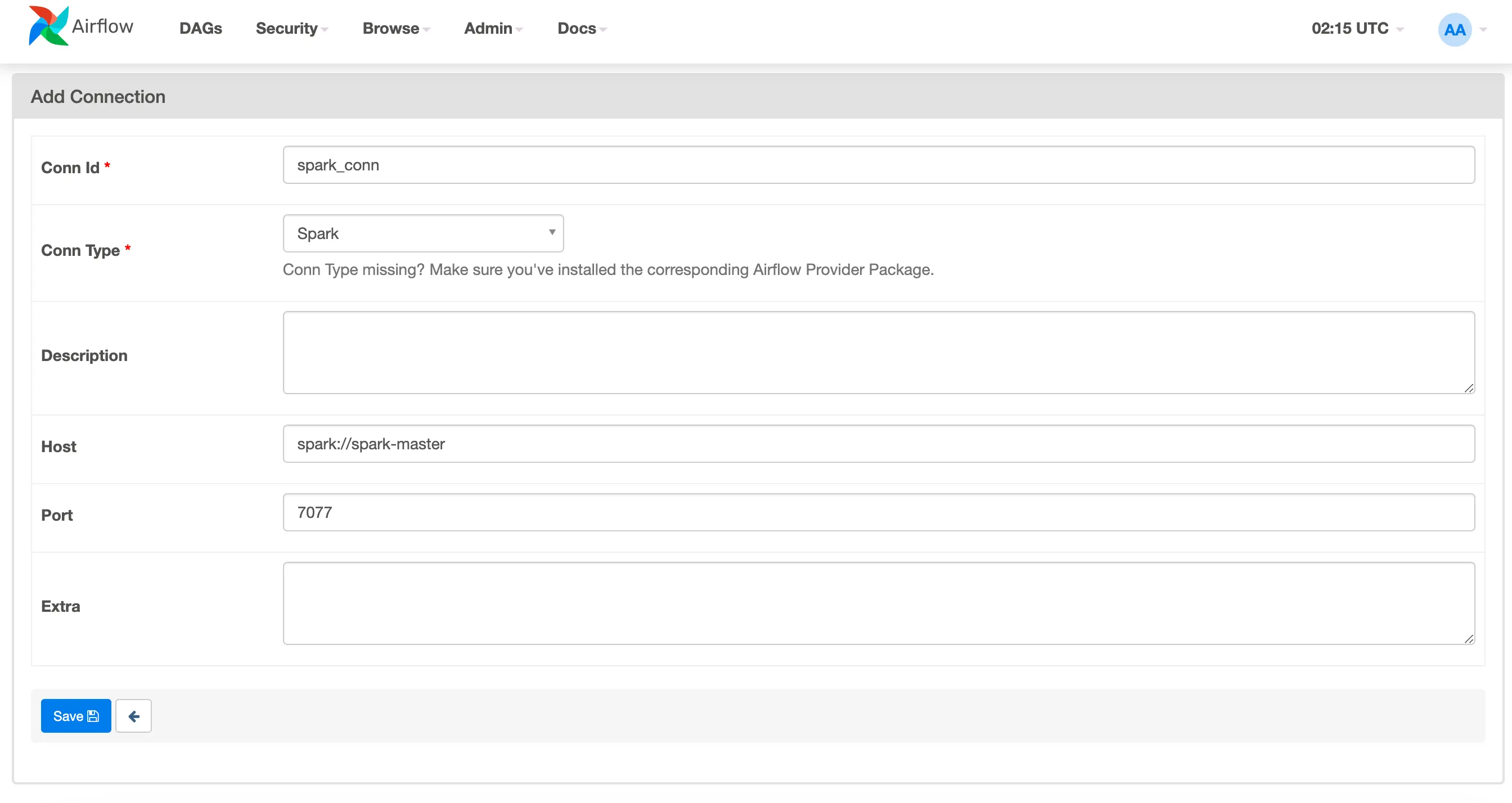
To set up the connection between Airflow and Spark, configure the settings as shown below and click the “save” button. It’s important to note that these values are the default settings, so be sure to use your own specific configuration if applicable. Once the configuration is saved, the connection between Airflow and Spark will be established.
4- Test your Task
It’s time to test our task to ensure it’s working correctly. We will explain how to test the added task without running the entire DAG here.
airflow tasks test AY_data_pipleine run_spark_job 2023-01-01If you’re not sure about the previous command, please refer to Tip #1 for Apache Airflow. It’s an essential tip that you should know.
So the image below shows the expected output after executing the previous command.
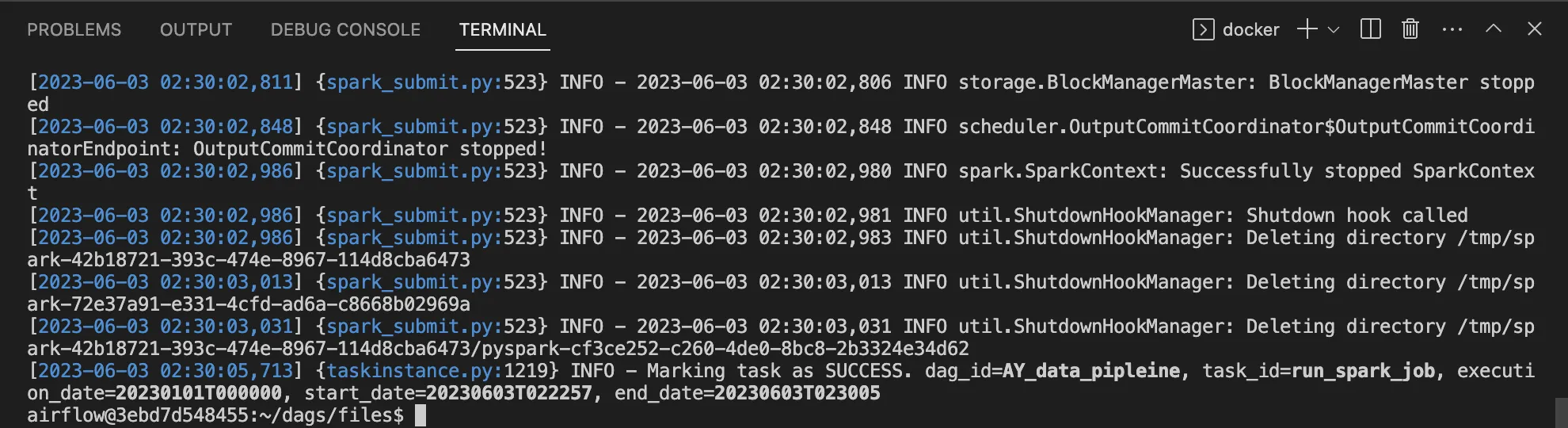
The image below shows that You run successfully the Spark job using Apache Airflow. Congratulations !!
In conclusion, the integration of Apache Spark with Apache Airflow provides a powerful solution for managing and executing complex data processing workflows. By utilizing Airflow’s workflow management capabilities and Spark’s distributed computing capabilities, users can create scalable and efficient data processing pipelines that can handle large amounts of data.
The SparkSubmitOperator in Airflow provides a simple and straightforward way to schedule and execute Spark jobs within Airflow’s DAGs. The many configurable parameters SparkSubmitOperator allow for fine-tuning of the Spark job’s performance and resource allocation, while the connection to the Spark cluster ensures that the job is executed on the correct platform.
Overall, the integration of Apache Spark and Apache Airflow enables data engineers and analysts to easily and efficiently manage their data processing pipelines, leading to faster and more accurate insights from their data.




One thought on “How to Schedule and Automate Spark Jobs Using Apache Airflow”