This is DBT Tutorial and you can download pdf material at the end of this article. Let’s start by stating that data transformation is a crucial part of modern data workflows. However, traditional methods of handling transformations in SQL can be tricky, lead to mistakes, and difficult to scale. This is where DBT (Data Build Tool) comes in. DBT simplifies the process of transforming, testing and documenting data in the cloud using SQL, making it an essential tool for data analysts and engineers.
Who Should Use DBT?
DBT is primarily designed for data analysts, engineers, and BI professionals who work with cloud-based data warehouses. It helps streamline the transformation process by providing reusable SQL-based models, automated testing, and version control.
What is DBT? And Why Should You Care?
DBT (Data Build Tool) is an open-source tool that enables data teams to transform raw data into clean, structured formats using SQL. It eliminates redundant SQL queries, promotes modularity, and enhances collaboration across teams.
ETL vs. ELT: Understanding the differences
- ETL (Extract, Transform, Load): Traditional approach where data is transformed before loading it into a data warehouse.
- ELT (Extract, Load, Transform): Modern approach where raw data is loaded into a cloud warehouse first, and then transformed using tools like DBT.
Challenges in Traditional Data Transformation Tools
Traditional data transformation methods come with several limitations that make the process inefficient, error-prone, and difficult to scale. The image highlights four major challenges faced by data teams when working with SQL-based transformations.
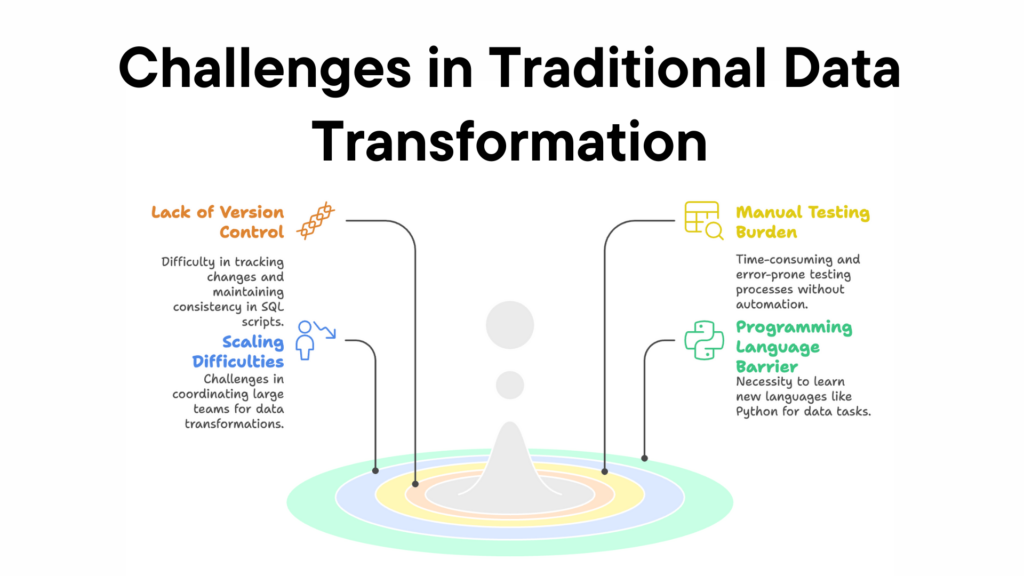
1. Lack of Version Control
- SQL scripts are often maintained in isolated files without proper versioning.
- Tracking changes and maintaining consistency becomes difficult when multiple people are involved.
- Without version control, rolling back to previous versions or understanding historical modifications is challenging.
2. Scaling Difficulties
- As data teams grow, coordinating transformations across multiple team members becomes complex.
- Large-scale transformations require collaboration, but traditional approaches lack proper tools to manage and track contributions effectively.
- Ensuring standardization and quality across a large team is difficult without automation.
3. Manual Testing Burden
- Testing SQL transformations manually is a time-consuming process.
- Without automated testing, errors may go unnoticed until they impact reports or dashboards.
- Debugging data issues manually is inefficient and prone to human error.
4. Programming Language Barrier
- Many transformation workflows require additional programming beyond SQL, such as Python for complex data manipulation.
- Analysts and business users may struggle with learning new programming languages just to perform transformations.
- This creates a bottleneck where only engineers proficient in multiple languages can handle advanced transformations.
The Power of DBT
DBT solves these challenges by introducing modularity, automation, and collaboration in data transformation. Here’s how:
1. Modularity: No More Copy-Pasting SQL
Traditional SQL workflows often require repetitive queries, leading to inefficiencies and inconsistencies.
- Before DBT: Every report required writing the same SQL logic repeatedly, increasing the risk of errors and maintenance challenges.
- With DBT: SQL logic is broken into reusable models, ensuring consistency, reducing duplication, and making transformations more manageable.
2. Jinja & Macros: Making SQL Dynamic
DBT leverages Jinja, a templating engine, to bring programming capabilities to SQL:
- Use control structures (e.g., loops and conditions) within SQL.
- Define environment variables for deployment flexibility.
Example: Using Jinja for Dynamic SQL
{% set payment_methods = ["bank_transfer", "credit_card", "gift_card"] %}
SELECT
order_id,
{% for payment_method in payment_methods %}
SUM(CASE WHEN payment_method = '{{payment_method}}' THEN amount END) AS {{payment_method}}_amount,
{% endfor %}
SUM(amount) AS total_amount
FROM app_data.payments
GROUP BY 1;
This query will get compiled to:
select
order_id,
sum(case when payment_method = 'bank_transfer' then amount end) as bank_transfer_amount,
sum(case when payment_method = 'credit_card' then amount end) as credit_card_amount,
sum(case when payment_method = 'gift_card' then amount end) as gift_card_amount,
sum(amount) as total_amount
from app_data.payments
group by 1
Macros: Reusable SQL Functions
Macros allow users to define reusable SQL functions.
{% macro get_payment_amount(payment_method) %}
SUM(CASE WHEN payment_method = '{{ payment_method }}' THEN amount END) AS {{ payment_method }}_amount
{% endmacro %}
This query will get compiled to:
SELECT
order_id,
{{ get_payment_amount('bank_transfer') }},
{{ get_payment_amount('credit_card') }},
{{ get_payment_amount('gift_card') }},
SUM(amount) AS total_amount
FROM app_data.payments
GROUP BY 1;
3. Automated Data Quality Testing
Data quality is an essential part of any analytics workflow, but issues are often discovered too late, leading to inaccurate insights and lost time. Automating this process can help catch errors early, reducing manual effort and the risk of errors in reporting.
- Before DBT: Data errors were only noticed when reports showed incorrect results, often causing delays in fixing issues. Without automation, manual checks were required, which could be inconsistent and time-consuming.
- With DBT: You can automate data quality testing by setting up specific tests for data integrity, uniqueness, null values, and relationships. This allows you to catch issues early, before they reach reports, ensuring data reliability and consistency.
4. Version Control & Collaboration (Git)
Version control is essential when multiple team members are collaborating on data projects. Without it, changes can get lost, and conflicts can arise when trying to reconcile edits made by different people.
- Before DBT: SQL files were stored in different team folders, with no versioning system in place. This created confusion when trying to track changes, and collaboration often led to overwriting or conflicting edits. Updates were hard to trace, and teams often worked in silos.
- With DBT: DBT integrates seamlessly with Git, providing a version control system that tracks every change made to your project. This allows multiple team members to work on the same project without the risk of conflict. With Git’s branching and merging capabilities, collaboration becomes smooth, and changes are easily traceable, reducing errors and improving team communication.
5. Build Data Lineage & Documentation
Having visibility into how data flows from source to destination is essential for troubleshooting, audits, and ensuring that transformations are being performed correctly. Without lineage, it’s difficult to understand or trust the outputs.
- Before DBT: There was no clear visibility into how data flowed through transformations. If something went wrong, it was difficult to pinpoint which step in the process caused the issue. Additionally, manual documentation was often outdated and incomplete, making it hard for new team members to get up to speed.
- With DBT: DBT automatically generates data lineage graphs that show how data is transformed across models, helping teams track dependencies between datasets. This built-in documentation makes it easy to understand the flow of data through the pipeline and helps maintain consistency and transparency. The lineage graphs are updated in real-time as transformations change, ensuring that documentation is always up to date.
6. Performance Optimization
When working with large datasets, performance can become a bottleneck, leading to slow data processing and delayed analysis. Optimizing performance is essential to ensure timely insights.
- Before DBT: Running transformations on large datasets was slow and inefficient, often requiring full reprocessing of data. This could take hours or even days, depending on the dataset’s size, which impacted the overall productivity and turnaround time for reports.
- With DBT: DBT introduces incremental models, allowing you to process only new or modified data, rather than re-running the entire dataset. This significantly reduces processing time and improves efficiency, particularly for large datasets. As a result, data pipelines are faster, and resources are better utilized, ensuring timely access to insights without sacrificing performance.
DBT Core vs. DBT Cloud
DBT offers two distinct versions tailored to different user needs: DBT Core, a free open-source tool for developers who prefer hands-on control, and DBT Cloud, a managed solution that simplifies deployment and collaboration. Understanding the differences between these versions will help you choose the right one for your data transformation needs.
DBT Core (Free & Open Source)
- Ideal for developers comfortable with a command-line interface.
- Requires manual setup and configuration.
- Offers complete flexibility for customization.
- Best suited for individual users and small teams who prefer self-hosted solutions.
DBT Cloud (Managed Solution)
- A fully managed, web-based platform requiring no manual setup.
- Provides an intuitive UI, eliminating the need for CLI interactions.
- Includes features like job scheduling, automated documentation, and team collaboration tools.
- Designed for teams and enterprises seeking scalability and ease of use without infrastructure management.
Conclusion
DBT is transforming the way data teams handle transformations. By using modular SQL, automation, version control, and performance optimizations, DBT empowers teams to create clean, efficient, and scalable data workflows.