“Data Warehouse vs Data Lake vs Data Lakehouse” is a topic that often confuses many people. In this blog, we will cover everything you need to know about the architecture of data warehouses, data lakes, and data lakehouses. We’ll explore the pros and cons of each, along with their features and examples. Let’s start!
Table of Contents
Data Warehouse
A data warehouse is a single, central place where historical data from different sources is combined. It gives a complete and consistent view of the business.
Data Warehouse architecture
A data warehouse architecture is a structured framework designed to enable the efficient storage, integration, and retrieval of large volumes of data from various sources. The architecture typically includes several layers, each serving a specific function in the process of data consolidation, storage, and analysis. Below is an explanation of the key components of a data warehouse architecture.
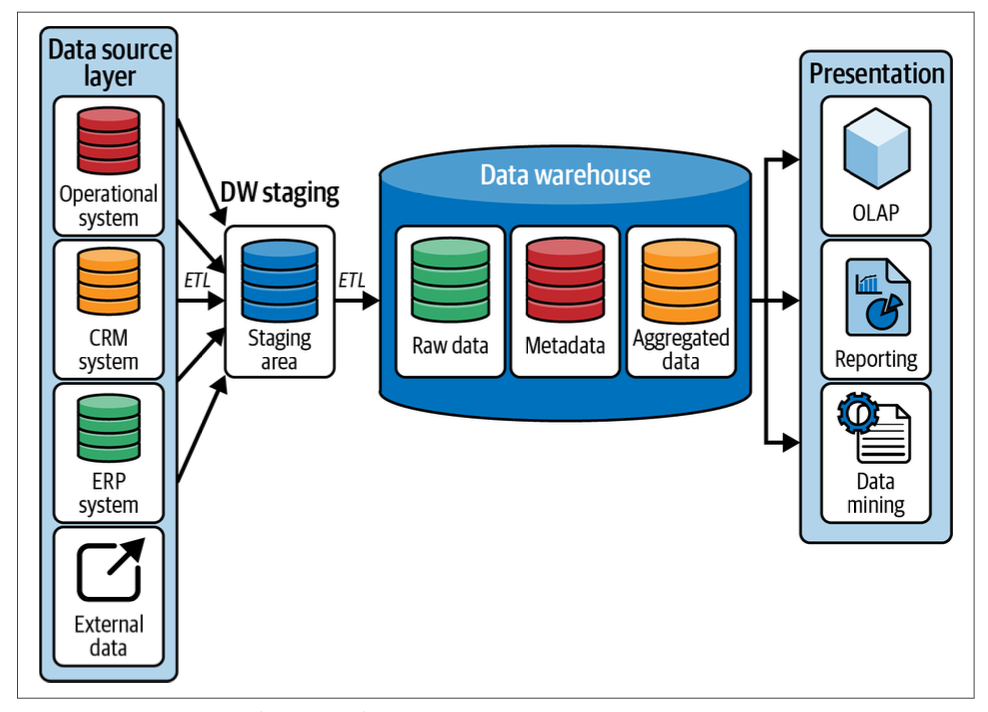
The image illustrates the flow of data from various source systems into the data warehouse and its subsequent use in analysis and reporting.
Key Components
- Data Source Layer:
- Operational System: These are databases that manage day-to-day operations, such as transaction processing.
- CRM System: Customer Relationship Management systems that store customer data.
- ERP System: Enterprise Resource Planning systems that manage business processes.
- External Data: Data obtained from external sources outside the organization.
- DW Staging Area:
- Staging Area: A temporary storage area where data from different sources is collected and prepared for loading into the data warehouse. The process involves ETL (Extract, Transform, Load), where data is extracted from source systems, transformed into a suitable format, and loaded into the staging area before being moved to the data warehouse.
- Data Warehouse:
- Raw Data: Unprocessed data directly loaded from the staging area.
- Metadata: Data about data, which helps in understanding and managing the data warehouse. It includes definitions, structures, and rules.
- Aggregated Data: Summarized data that is aggregated to facilitate quick analysis and reporting.
- Presentation Layer:
- OLAP (Online Analytical Processing): Tools that allow for complex analytical queries and multidimensional data analysis.
- Reporting: Systems and tools used to generate reports from the data warehouse, providing insights and business intelligence.
- Data Mining: Techniques and tools used to discover patterns and relationships in the data, often used for predictive analytics.
This architecture ensures that data from multiple sources is integrated, providing a comprehensive and unified view of the business for analysis and decision-making.
Dimensional Modeling
Dimensional modeling is an essential technique for designing data warehouses to support effective and efficient data analysis. This methodology emerged to address the need for a comprehensive data model that spans different subject areas within a corporate enterprise.
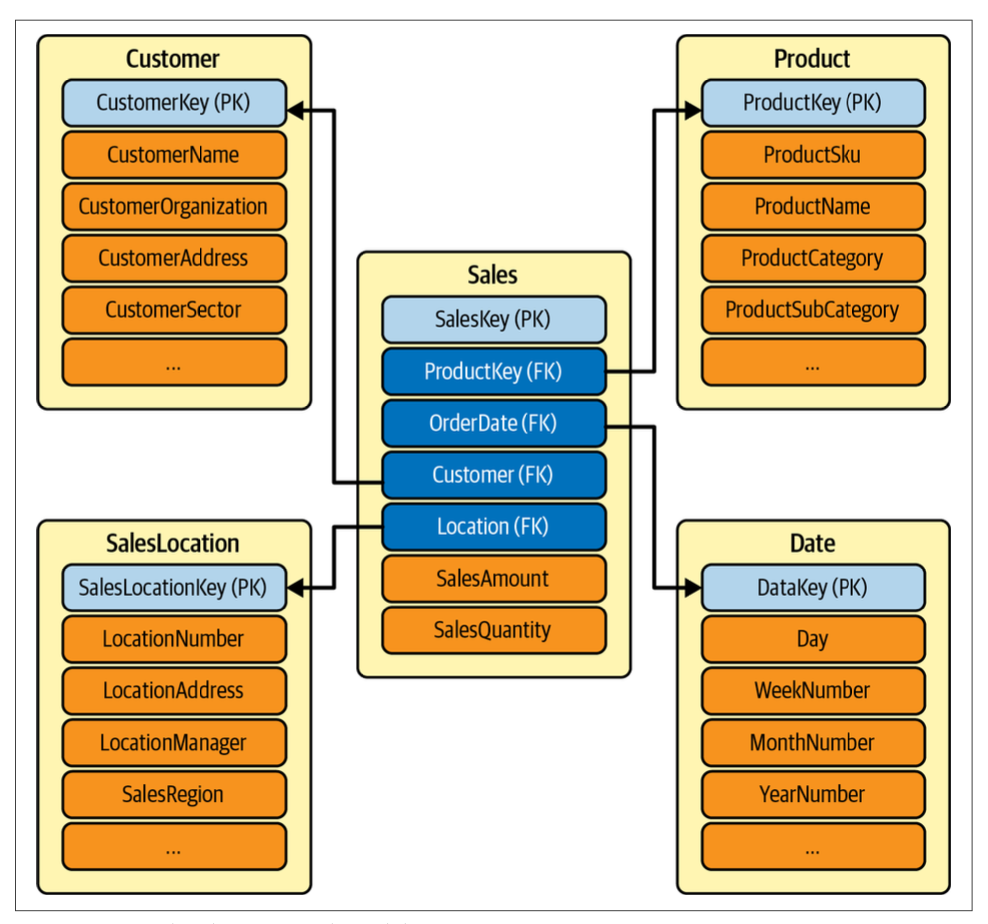
A dimensional model is typically described using a star schema. A star schema organizes data related to a specific business process, such as sales, into a structure that facilitates easy analytics. It comprises two main components:
- Fact Table: This is the central table in the schema that captures the primary measurements, metrics, or “facts” of the business process. For instance, in the context of a sales process, a sales fact table would include data like units sold and sales amount. Fact tables have a well-defined grain, which refers to the level of detail recorded. For example, a sales fact table can have low granularity if it summarizes data annually, or high granularity if it includes details by date, store, and customer identifier.
- Dimension Tables: These tables are related to the fact table and provide context to the business process being analyzed. In a sales scenario, the dimension tables might include information on products, customers, salespersons, and stores. These tables surround the fact table, creating a star-like structure, which is why this schema is referred to as a “star schema.”
The star schema’s structure, linking fact tables to their associated dimension tables through primary and foreign key relationships, simplifies and enhances the process of data analysis, making it a preferred choice for designing data warehouses.
Data Warehouse pros
There are many pros for Data warehouse .
- High-Quality Data: Data warehouses provide cleansed and normalized data from various sources in a common format, ensuring consistency across departments.
- Historical Insights: Storing large amounts of historical data enables users to analyze trends over different periods.
- Reliability: Based on relational database technology, data warehouses support ACID transactions, ensuring data reliability.
- Standard Modeling Techniques: Use of star-schema modeling techniques with fact and dimension tables, and availability of prebuilt templates for quick development.
- Business Intelligence and Reporting: Ideal for generating actionable insights for various departments (marketing, finance, operations, sales) using BI tools, effectively answering the “What happened?” question.
Data Warehouse cons
- Volume Challenges: Struggle with exponentially increasing data volumes, leading to storage and scalability issues.
- Velocity Limitations: Not suited for handling the fast pace of big data; lack support for real-time data streaming and have limited ETL processing windows.
- Variety Issues: Not well-suited for storing and querying semi-structured or unstructured data types, requiring additional preprocessing.
- Veracity Concerns: Lack built-in support for tracking data trustworthiness; metadata focuses more on schema than on data quality and lineage.
- Proprietary and Costly: Use of a closed, proprietary format limits compatibility with data science and machine learning tools, making them expensive to build and maintain.
These limitations of traditional data warehouses have led to the development of modern data architectures, like data lakes, to better handle the volume, velocity, variety, and veracity of big data.
Data lake
Because data warehouses lack the capability to handle unstructured and semi-structured data, data lakes were introduced. A data lake is a centralized repository designed to store, process, and analyze large volumes of diverse data formats, ranging from structured to unstructured data. The architecture of a data lake enables organizations to harness more data from various sources and make it accessible for different types of analysis and processing. Below is an explanation of the key components of a data lake architecture.
The image illustrates the flow and usage of data within a data lake architecture:
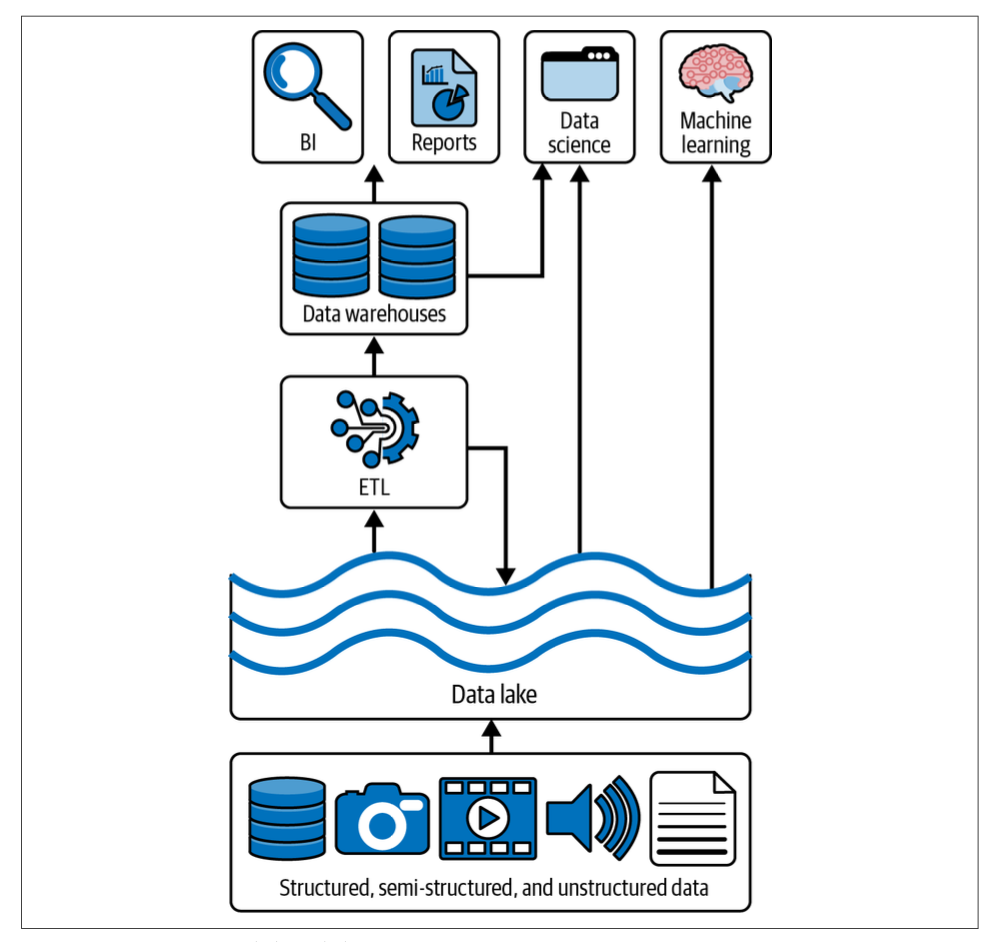
Key Components:
- Data Sources:
- Structured Data: Data that is highly organized, such as databases and spreadsheets.
- Semi-Structured Data: Data that is partially organized, such as JSON or XML files.
- Unstructured Data: Data that lacks a specific format, such as images, videos, and audio files.
- Data Lake:
- A large storage repository that holds a vast amount of raw data in its native format. This allows for flexible data processing and retrieval, accommodating the varying needs of different data users.
- ETL (Extract, Transform, Load):
- The process through which data is extracted from various sources, transformed into a suitable format, and loaded into data warehouses for structured analysis.
- Data Warehouses:
- These are structured storage systems that house processed and organized data, making it easier for businesses to conduct detailed analysis and reporting.
- Usage and Analysis:
- Business Intelligence (BI): Tools and applications that analyze data to provide actionable business insights.
- Reports: Generated documents that summarize data findings, trends, and metrics.
- Data Science: Advanced analytics that use statistical models and algorithms to extract meaningful insights from data.
- Machine Learning: A branch of artificial intelligence that uses data to train models for predictive analysis and automation.
Data Lake pros
- Centralized Data Storage: Consolidate all data assets into one central location.
- Format Agnostic: Support various data formats (e.g., Parquet, Avro) for smooth interoperability with different tools and systems.
- Scalability: Deployed on mature cloud storage systems, benefiting from easy scalability, monitoring, and low storage costs.
- Supports All Data Types: Handle structured, semi-structured, and unstructured data, making them suitable for various workloads, including media processing.
- High Throughput: Ideal for streaming use cases, such as IoT data, media streaming, and web clickstreams.
Data Lake cons
- High Expertise Required: Building and maintaining a data lake requires expert skills, leading to high staffing or consulting costs.
- Expensive Data Transformation: Transforming raw data into business-ready formats can be costly and time-consuming.
- Poor Query Performance: Traditional data lakes have slow query performance, necessitating additional processing and loading into data warehouses.
- Data Quality Issues: Using a “schema on read” strategy can lead to data quality problems, potentially turning the data lake into a “data swamp.”
- No Transactional Guarantees: Lack of transactional support means data updates are expensive and inefficient, leading to issues like the “small file problem.”
While data lakes address many data storage needs, their limitations have led to the development of new architectures, such as the data lakehouse, which combines the strengths of both data warehouses and data lakes.
Data Lakehouse:
A data lakehouse combines the benefits of both data lakes and data warehouses:
- Low Cost and Flexibility: Like data lakes, it uses cheap cloud storage that is flexible and scalable.
- Advanced Data Management: Like data warehouses, it supports features like ACID transactions (ensuring data accuracy and reliability), data versioning, auditing, indexing, caching, and query optimization.
Key Features:
- High-Performance Formats: Uses data formats like Parquet, which are fast and efficient.
- ACID Transactions: Ensures that all operations on the data are reliable and follow strict rules for accuracy.
- Open-Table Format: Adds advanced features to existing data formats, making data management easier and more reliable.
Data Lakehouse Pros
- Single Data Copy: No need to duplicate data between a data lake and a data warehouse.
- Efficient Performance: Access data from the lake with performance similar to a traditional data warehouse.
- Cost Savings: Lower costs due to reduced data movement and leveraging affordable cloud storage.
- Simplified ETL: Easier data processing with fewer steps, reducing chances of data quality issues.
- Quick Development: Combines large data storage with refined models, speeding up development and reducing time to value.
A data lakehouse merges the best parts of data lakes and data warehouses, offering a cost-effective, flexible, and reliable solution for managing and analyzing large amounts of data.
Data Warehouse vs Data Lake vs Data Lakehouse
The following table provides a comparison to help understand the strengths and weaknesses of each architecture, aiding in selecting the right solution for your business needs.
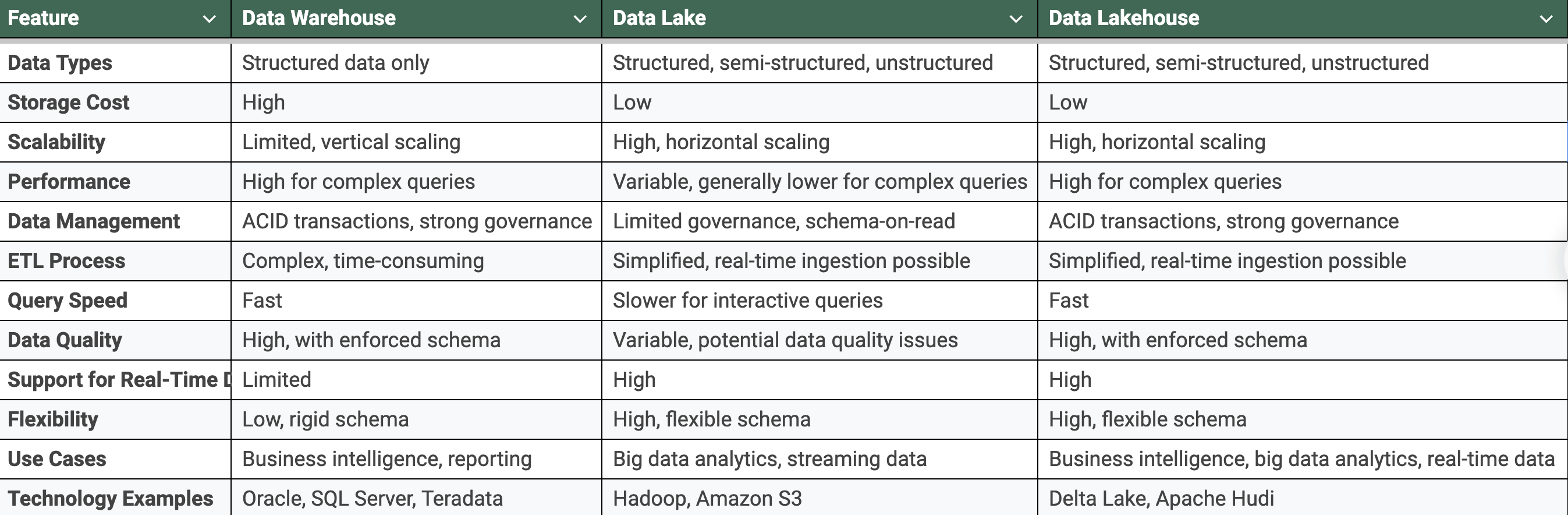
Conclusion
Choosing the right data architecture is essential for making the most out of your data. Traditional data warehouses have been reliable for business intelligence, providing structured and accurate data. However, they can be expensive and inflexible. Data lakes offer a way to store large amounts of different types of data at a lower cost, but they sometimes struggle with data quality and slow performance.
Data lakehouses bring together the benefits of both data warehouses and data lakes. They offer the flexibility and cost-effectiveness of data lakes while maintaining the reliable data management and performance of data warehouses. This combination makes data lakehouses a strong choice for managing and analyzing large volumes of data.
In summary, each type of architecture has its advantages, but data lakehouses provide a balanced solution for today’s data needs. They allow businesses to manage and use their data more efficiently and accurately, making it easier to make informed decisions.
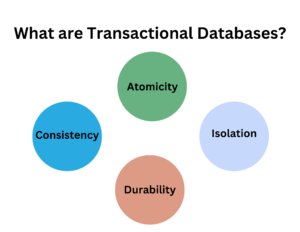
Read more about What are Transactional Databases? , Data Warehouse vs. Data Mart vs. Data Lake