
Table of Contents
Data Warehouse, Data Mart, and Data Lake are three fundamental structures in the landscape of data management, each serving a unique purpose and providing distinct advantages for handling vast amounts of data. This article explores the details of each system, outlining their architectures, primary use cases, and the scenarios in which each is most beneficial. By understanding these differences, organizations can make informed decisions about which system aligns best with their operational needs and strategic goals, thereby optimizing their data-handling capabilities for enhanced decision-making and operational efficiency.
What is a Data Warehouse?
A data warehouse is a centralized repository designed to store integrated data from multiple heterogeneous sources. Data within a warehouse is processed and structured for query and analysis, supporting business intelligence activities.
Data Warehouse Architecture
A data warehouse is structured to organize and use large amounts of data efficiently. Here’s a simple breakdown of each part of its architecture:
Data Source Layer
- Purpose: This first layer collects data from various places where information is stored, such as company databases, customer relationship management (CRM) systems, and enterprise resource planning (ERP) systems.
- How it Works: It pulls together all the different data from across the organization into one place.
Data Staging Area
- Purpose: Before the data can be used, it needs to be cleaned up and converted into a consistent format.
- Process: This layer is all about preparing the data by cleaning it (removing errors or duplicates), transforming it (changing data formats or combining data from different sources), and getting it ready to be stored and used.
Data Storage Layer
- Purpose: Once the data is cleaned and organized, it’s stored in this layer.
- How Data is Stored: The data is kept in a structured format in relational databases, which makes it easier to manage and retrieve.
Data Presentation Layer
- Purpose: This layer organizes the data into a format that is easy for users to understand and analyze.
- Function: It involves summarizing the data and organizing it in tables, charts, or reports that make sense for business analysis.
Access Tools
- Purpose: These tools are used to access and analyze the data stored in the data warehouse.
- Tools Used: Includes business intelligence software, query tools, and applications that help users retrieve and make sense of the data.
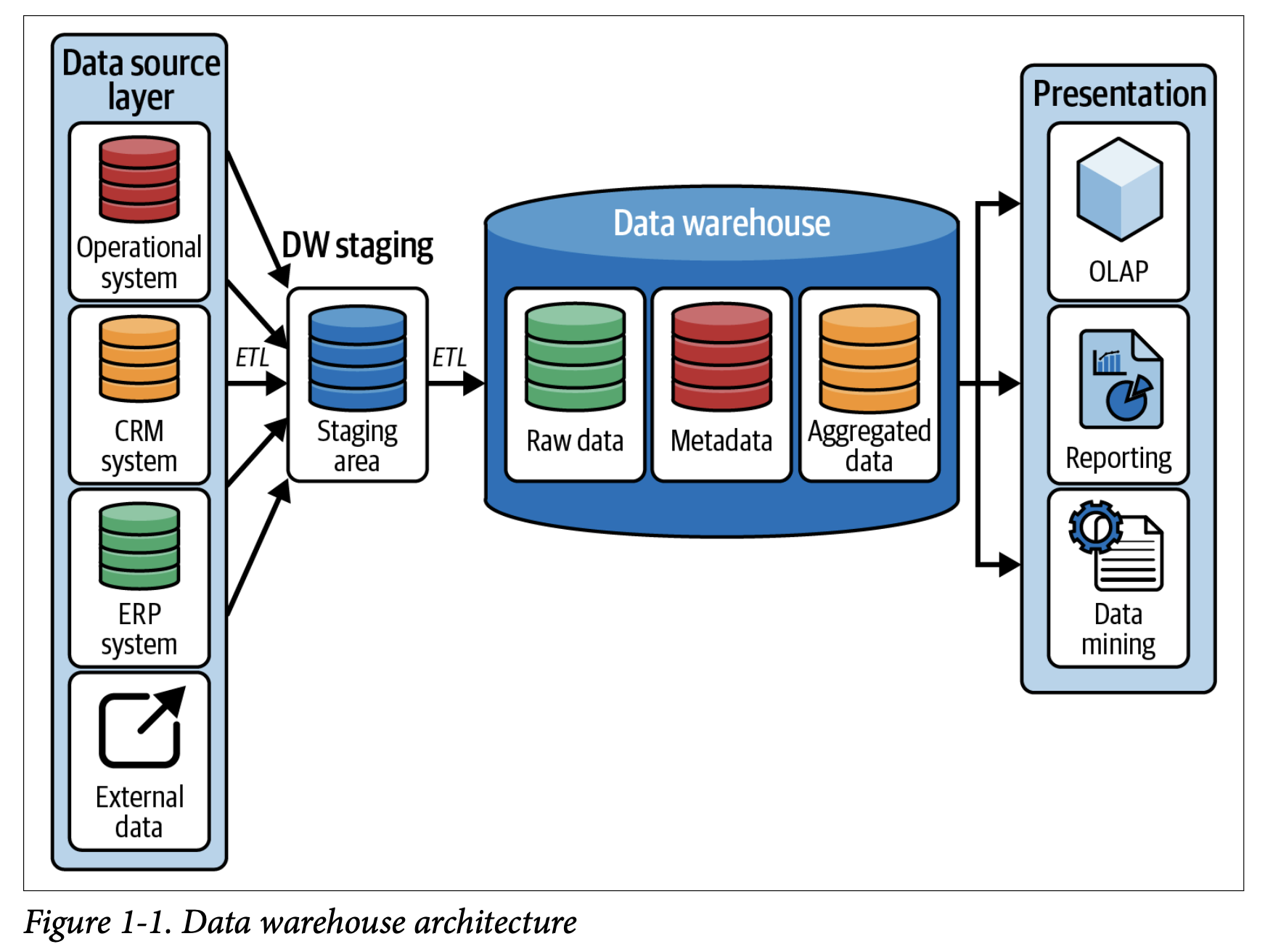
In essence, a data warehouse collects data from various sources, cleans and organizes it, and then stores it in a way that’s easy to access and analyze, helping businesses make informed decisions based on their data.
Data Warehouse Use Cases
A data warehouse serves as a powerful tool for managing and analyzing large amounts of organizational data. Below are some common ways businesses utilize data warehouses:
- Business Intelligence: Enhancing decision-making through comprehensive BI tools.
- Reporting and Analysis: Providing structured data for operational reporting and trend analysis.
- Data Mining: Using sophisticated algorithms to discover patterns and relationships.
What is a Data Mart?
A data mart is a subset of a data warehouse, designed to cater to the specific needs of a particular business line or department. It is smaller, more focused, and can be optimized for a particular subject area or specialized function.
Data Mart vs Data Warehouse
When comparing data marts to data warehouses, it’s essential to understand their distinct roles and functionalities within an organization’s data strategy. Here’s a more detailed look at their differences in scope, performance, and cost:
Scope
- Data Mart: A data mart serves a specific segment of an organization, such as a single department or team. It is designed to address particular problems or answer specific sets of questions relevant to its focused area. Because of this specialization, data marts contain only the data necessary for their defined purpose, which simplifies the data models and reduces the volume of data stored.
- Data Warehouse: In contrast, a data warehouse integrates data from across the entire organization, providing a comprehensive view of the enterprise. This broad scope supports wide-ranging, complex queries that cater to general reporting and decision-making needs at the organizational level. A data warehouse is built to handle large volumes of data from disparate sources, making it a central part of enterprise-wide data systems.
Performance
- Data Mart: The focused nature of a data mart not only simplifies management but also enhances performance. With a smaller dataset to query, response times are typically quicker, making data marts ideal for rapid, targeted insights. This is particularly beneficial for specific groups within the organization that require fast, frequent access to data.
- Data Warehouse: While data warehouses provide valuable insights, their large-scale and complexity can lead to slower query performance, especially when handling very large datasets and complex queries across multiple data sources. Performance tuning and more advanced data processing technologies are often needed to maintain speed and efficiency.
Cost
- Data Mart: Implementing a data mart is generally less costly than setting up a full-scale data warehouse. The smaller scale of data marts means they require less hardware and software resources, and they are simpler to design and maintain. This makes data marts a cost-effective solution for departments with specific data needs that do not require the full complexity and breadth of a data warehouse.
- Data Warehouse: The cost of implementing and maintaining a data warehouse can be significantly higher. The integration of diverse data sources, along with the need for extensive storage capacity and powerful processing capabilities, increases the initial and ongoing expenses. Additionally, data warehouses often require a team of IT specialists to manage their operations and ensure data quality and consistency, which adds to the overall cost.
Understanding these distinctions helps organizations tailor their data management strategy to match their specific needs, balancing scope, performance, and cost to achieve the most effective data handling solutions.
Data Mart Architecture
A data mart is like a smaller, specialized store of data that serves specific departments within an organization. Here’s an easy-to-understand breakdown of its structure:
Source Data
- Purpose: This component is where the data mart gets its information. It pulls data either from different internal departments within the company or from external data sources.
- How it Works: The data gathered is specific to the needs of a particular department or business function.
Integration Layer
- Purpose: Before the data can be used effectively, it needs to be cleaned and standardized.
- Process: This layer focuses on making sure the data is accurate and consistent by removing errors, aligning mismatched data from different sources, and transforming it into a format that can be easily used in the data mart.
Storage
- Purpose: This is where the prepared data is kept.
- How Data is Stored: It’s usually stored in a relational database format, which organizes the data into tables and makes it easy to manage and retrieve.
Presentation
- Purpose: Data needs to be presented in a way that is useful and accessible to its users.
- Function: This final layer tailors the data presentation to the specific requirements of its users, such as departmental managers or analysts. It could be in the form of reports, dashboards, or visual analytics that help users make decisions based on the data.
In summary, a data mart provides a focused view of data for specific areas of an organization, ensuring that data is collected, cleaned, stored, and presented in ways that are most useful to its intended users.
Data Mart Use Cases
Data marts are specialized tools that are used to address the specific needs of individual departments within an organization, enabling targeted analysis and reporting. Here are some common use cases for data marts:
- Departmental Analysis: Facilitates deep, specialized analysis for specific departments.
- Quick Deployment: Can be quickly deployed to address urgent analytical needs.
- Cost Efficiency: Provides a cost-effective solution for small-scale BI implementations.
What is a Data Lake?
A data lake is a large-scale storage repository that holds a vast amount of raw data in its native format until it is needed. Unlike a data warehouse, a data lake can handle structured, semi-structured, and unstructured data.
Data Lake vs Data Warehouse
When deciding between a data lake and a data warehouse, understanding their distinct approaches to handling data structure, scalability, and data types is crucial. Here’s an expanded look at these key differences:
Data Structure
- Data Lake: Data lakes are designed to store vast amounts of raw data in their native format. There is no predefined schema applied to the data when it is first captured. Instead, the schema is imposed on the data as and when it is read for specific analytical purposes. This method, known as schema-on-read, provides high flexibility allowing data lakes to store all types of data without initial processing. However, this flexibility can lead to challenges in querying the data efficiently because the data is not organized until it is needed for analysis.
- Data Warehouse: Unlike data lakes, data warehouses involve a schema-on-write approach where data is first processed and structured according to a predefined schema before being stored. This organization optimizes data warehouses for efficient querying and analysis, making them ideal for routine business intelligence and reporting tasks. The structured nature of data warehouses simplifies data management but at the expense of flexibility in handling unstructured data.
Scalability
- Data Lake: Data lakes excel in scalability, capable of storing petabytes of data with ease. Their structure allows them to scale horizontally by adding more servers into the pool. This is particularly advantageous for businesses that generate vast amounts of data daily and need a cost-effective, scalable solution to store unstructured or semi-structured data, including binary data, logs, and images. The ability to scale extensively and economically is a defining strength of data lakes.
- Data Warehouse: While data warehouses can also scale to support large volumes of data, their reliance on structured data and complex schemas makes scaling more expensive and technically challenging. The cost of additional storage and processing power, along with the need to maintain the integrity of the schema across an expanding dataset, can limit the scalability of traditional data warehouses.
Data Types
- Data Lake: One of the most significant advantages of a data lake is its ability to handle a wide variety of data types. From structured data from traditional databases to semi-structured data like JSON, XML, and even unstructured data such as text, multimedia, and sensor data, data lakes can store it all. This capability makes data lakes particularly useful for applications involving big data, machine learning, and real-time analytics, where diverse data forms are common.
- Data Warehouse: Data warehouses are primarily designed to manage structured data. They are optimized to perform well with data that fits into tables with rows and columns, such as financial records, sales data, and customer information. While modern data warehouses have started to adapt to handle semi-structured data, they are still primarily focused on structured data and are not as versatile as data lakes in managing different data types.
In summary, choosing between a data lake and a data warehouse largely depends on the specific needs related to data flexibility, scalability, and variety. Data lakes offer a more adaptable and scalable solution for handling diverse and voluminous data sets, whereas data warehouses provide a highly organized, efficient environment for structured data analysis and reporting.
Data Lake Architecture
A data lake is a system designed to store a huge amount of different types of data. Here’s a simplified explanation of each part of its architecture:
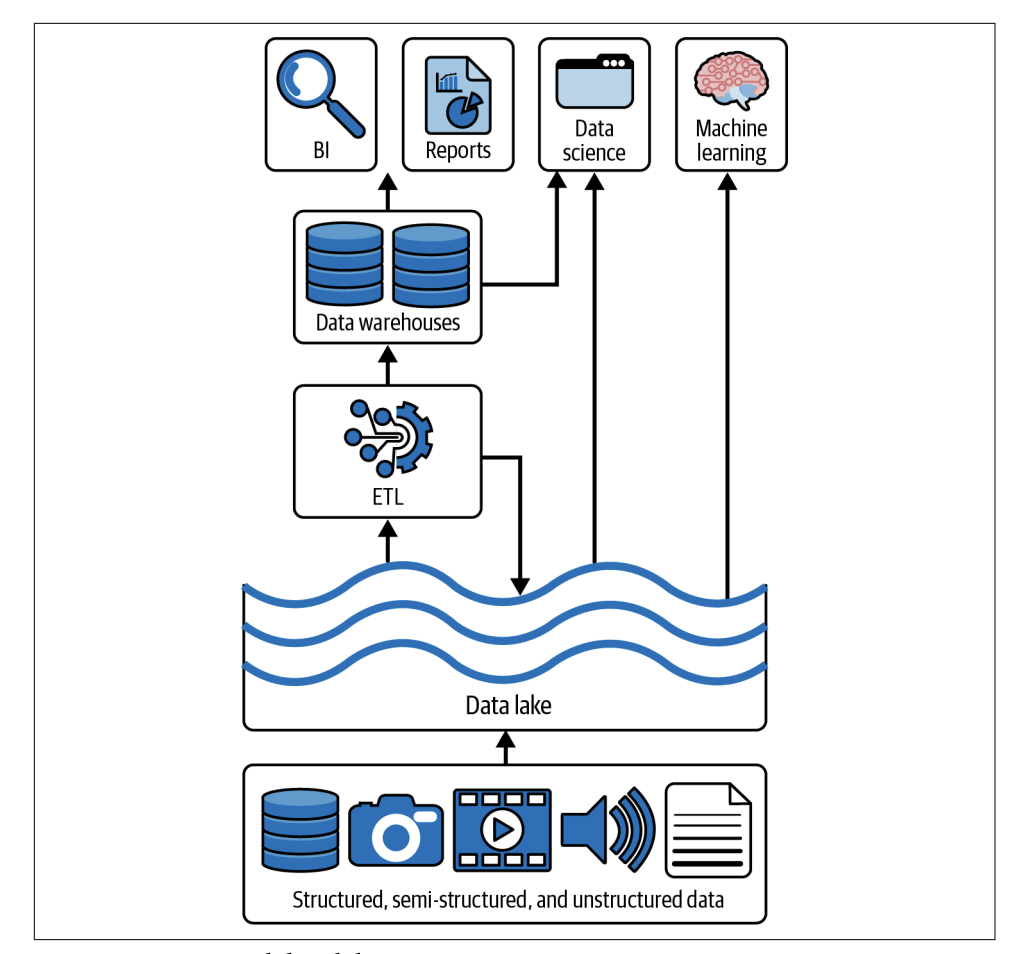
Data Ingestion Layer
- Purpose: This layer’s job is to gather data from many different sources. These sources might include things like business software (ERP, CRM), social media, or sensors.
- How it Works: Data can be collected all at once at specific times (batch mode), or it can be streamed continuously in real time, depending on what the business needs.
- Tools Used: Tools like Apache Kafka can stream data in real time, Apache Flume can manage large data logs, and ETL tools handle batch data processing.
Storage Layer
- Purpose: After data is collected, it’s stored just as it is, without any changes. This allows businesses to keep all their data without having to organize it first.
- How Data is Stored: The data lake uses storage systems that can hold different types of data, from very organized data (like databases) to less organized data (like emails or videos).
Processing Layer
- Purpose: This part of the data lake uses tools to sort through and use the data as needed.
- Tools Used: Software like Hadoop or Spark can quickly process large amounts of data for various tasks.
Analytics and Consumption Layer
- Purpose: This is where data scientists and analysts work with the data. They analyze it to find insights and make decisions.
- Process: They use analytics tools to explore the data, looking for patterns or useful information that can help the business.
In short, a data lake allows a company to store all kinds of data in its original form, processes it when needed, and uses it for analysis to help make better business decisions.
Data Lake Use Cases
Data lakes are versatile storage solutions that can accommodate vast amounts of raw data in various formats. They are particularly useful in scenarios requiring extensive data processing and analysis. Here are some prominent use cases for data lakes:
- Big Data Processing: Ideal for massive volumes of diverse data.
- Real-Time Analytics: Supports real-time data processing and analytics.
- Advanced Analytics: Facilitates complex analytical tasks like predictive modeling and machine learning.
- Cost-Effective Scalability: Provides a cost-efficient storage solution as data volume grows exponentially.
Data Warehouse vs. Data Mart vs. Data Lake
Here is a comparison table that outlines the key differences between a data warehouse, data mart, and data lake across various aspects:
| Feature | Data Warehouse | Data Mart | Data Lake |
|---|---|---|---|
| Purpose | Centralized repository for enterprise-wide data | Specialized subset of data for specific use | Storage for raw data in native format |
| Scope | Organizational-wide | Departmental or specific business area | Extremely large-scale, diverse data |
| Data Types | Structured | Structured | Structured, semi-structured, unstructured |
| Schema | Defined at the time of data entry (schema-on-write) | Defined at the time of data entry (schema-on-write) | Defined at the time of use (schema-on-read) |
| Storage Format | Highly organized, relational databases | Highly organized, relational databases | File or object storage, less organized |
| Use Cases | Business intelligence, reporting, data mining | Deep, specialized analysis for departments | Big data processing, real-time analytics |
| Query Performance | Optimized for complex queries | Optimized for specific queries | Requires processing for optimized queries |
| Scalability | Scalable but complex and costly to scale | Less scalable, focused scope | Highly scalable, handles petabytes of data |
| Cost | High initial investment, maintenance | Lower cost due to limited scope | Cost-effective at scale |
| Implementation Time | Longer due to complexity and scale | Quicker due to limited scope | Variable, depends on specific use cases |
For a more comprehensive understanding, please watch the video below.
Conclusion
Understanding the distinctions and appropriate applications of data warehouses, data marts, and data lakes is crucial for organizations aiming to optimize their data management and analytics capabilities.
- Data Warehouses offer a robust architecture for enterprise-wide analytics, providing integrated, consistent data sets that are optimized for efficient querying and reporting. They are best suited for environments where the integrity and uniformity of data are paramount.
- Data Marts, being subsets of data warehouses, are ideal for department-specific insights. They enable faster response times and lower costs, with a focus on specific business areas or teams. This specialization can significantly enhance decision-making efficiency within departments.
- Data Lakes, with their ability to store vast amounts of raw data in varied formats, are the go-to solutions for businesses dealing with big data and needing extensive scalability. They are particularly beneficial when advanced analytical techniques, such as predictive analytics and real-time processing, are required.
In conclusion, the choice between a data warehouse, data mart, and data lake depends on the specific needs, data strategies, and objectives of the organization. By aligning the choice of technology with business goals, companies can ensure they are not only storing data efficiently but also maximizing their insights and value from this data.
Also explore: What Is The Difference Between A Data Lake And A Delta Lake?



