As a data engineer, your job is to create powerful solutions for handling large amounts of data. You start by collecting data from different sources. Then, you clean, organize, and combine the data to make it useful. Finally, you present the data in a way that other applications can easily use. Your goal is to build a smooth process that efficiently manages data and makes it accessible for different purposes. By doing this, you enable other people to make informed decisions based on accurate and reliable information.
Delta Lake has emerged as one of the most recent and powerful tools available to data engineers. It simplifies the job of a data engineer by providing an efficient and user-friendly platform to work with.
This article will provide you with a solid understanding of what Delta Lake is and enable you to differentiate between a data warehouse, a data lake, and Delta Lake. Take a moment to relax, and let’s begin.
Table of Contents
What is a data warehouse?
Before explaining what Delta Lake is, it is essential to understand what a data warehouse is. This understanding will assist us in establishing a strong and straightforward foundation.
In simple terms, a data warehouse is a centralized and organized repository that stores large amounts of structured data from various sources. It is designed to support reporting, analysis, and decision-making processes. A data warehouse consolidates structured data from different systems, transforms it into a consistent format, and structures it for efficient querying and analysis. One of the key advantages of a data warehouse is that it supports ACID transactions, ensuring data integrity and reliability. Its primary purpose is to provide users with a reliable and unified view of structured data for business intelligence and reporting purposes.
what are ACID transactions?
ACID transactions are a set of properties that make sure database operations are reliable and consistent.
- Atomicity: Transactions are treated as a single unit of work. Either all changes in a transaction are saved, or none of them are.
- Consistency: Transactions bring the database from one valid state to another, keeping the data consistent.
- Isolation: Transactions are isolated from each other to prevent interference or conflicts.
- Durability: Once a transaction is saved, its changes are permanent and will survive system failures.
ACID transactions ensure that database operations are trustworthy and maintain data integrity, even when multiple operations are happening at the same time or if there are system failures.
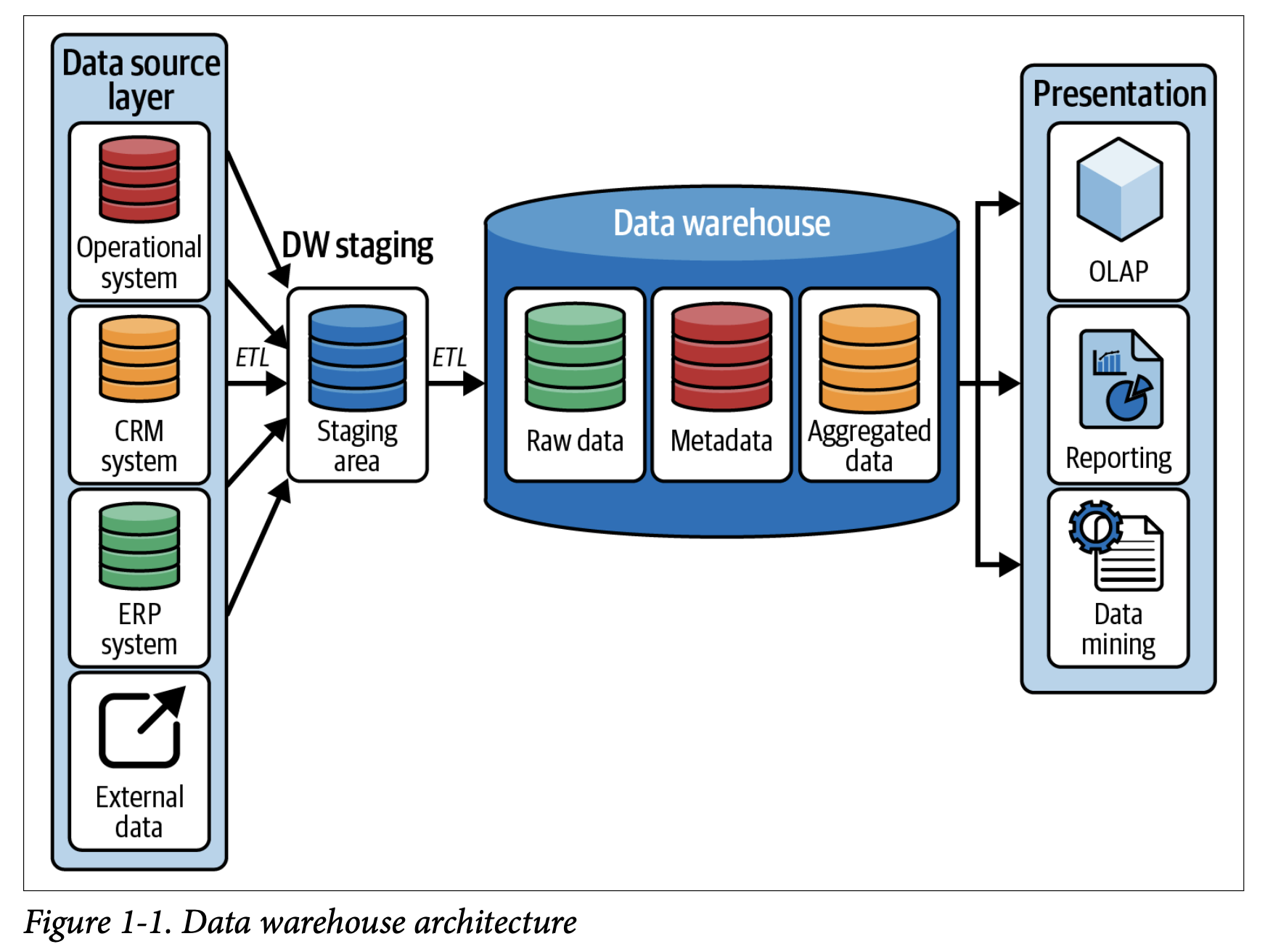
As we can see from the image above, the data warehouse architecture includes:
- Data Source Layer: Collects data from various sources.
- Data Staging Area: Prepares data for the data warehouse.
- ETL Process: Extracts, transforms, and loads data into the warehouse.
- Data Warehouse: Stores integrated and structured data.
- Presentation Layer: Provides user interfaces and reporting tools.
- OLAP: Enables complex analytical queries.
- Metadata: Describes the data warehouse structure.
- Data Mining: Extracts insights from the data.
- External Data: Integrates data from external sources.
After explaining what a data warehouse is, we note that data warehouses primarily process structured data. However, what happens when we encounter semi-structured data like logs or unstructured data such as images, audio, and videos? This is where the concept of a data lake comes into play. Let’s now delve into what a data lake is and how it addresses these types of data.
What is a data lake?
A data lake is a centralized repository that stores large volumes of raw, unprocessed, and diverse data in its native format. It is designed to accommodate structured, semi-structured, and unstructured data from various sources such as databases, files, sensors, social media, and more. Unlike traditional data storage approaches, data lakes do not enforce a predefined schema or require extensive data transformation upfront.

As we can see from the image above, Data lakes are a modern data storage and processing platform that can store and analyze all types of data, including structured, semi-structured, and unstructured data. They are scalable, cost-effective, and flexible. Data lakes are designed to store data in its raw, unprocessed state, without any upfront transformations or cleansing. This allows organizations to store all of their data, regardless of its format or structure, and access it for various purposes later on. The flexibility of storing data in its raw form is one of the key advantages of data lakes over traditional data warehouses, which require data to be pre-processed and structured before it can be stored and analyzed.
One limitation of data lakes is the lack of built-in support for ACID transactions. ACID transactions ensure data reliability and consistency. This limitation led to the emergence of Delta Lake, which addresses this problem by adding transactional capabilities, enabling ACID transactions, and enhancing the reliability and integrity of data lakes.
What is a delta lake?
Delta Lake is a storage layer that adds reliability, ACID transactions, and schema enforcement to data lakes. It improves traditional data lakes by offering features commonly found in data warehouses, making it a valuable tool for managing and processing data in a lakehouse architecture.
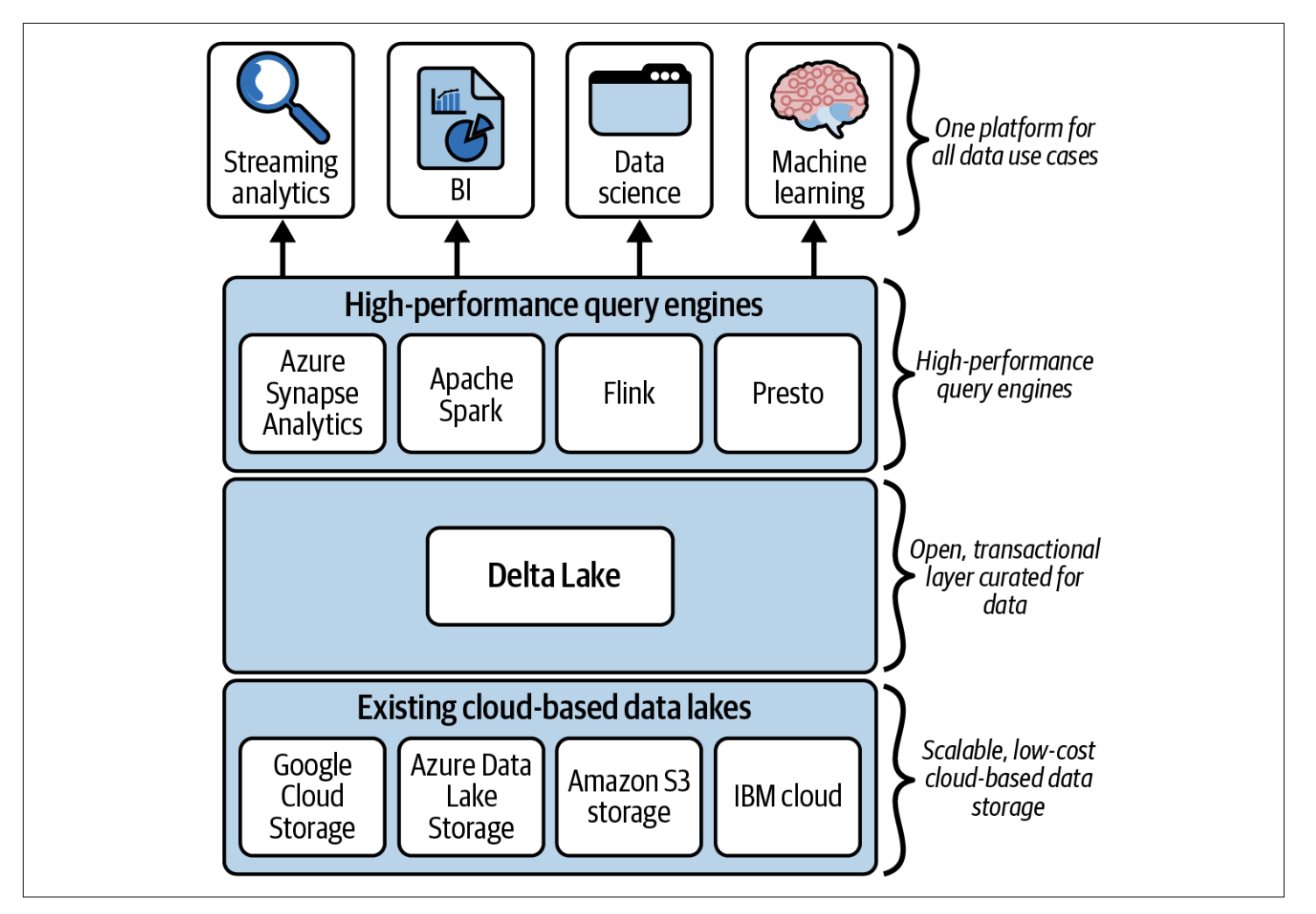
This is an infographic that describes the Delta Lake architecture, which is a data lake storage layer that offers transactional consistency, scalable performance, and unified access to data across various data processing frameworks. It is a new storage layer that sits on top of existing public cloud data lakes like Amazon S3, Azure Data Lake Storage, or Google Cloud Storage.
The infographic highlights the key features of Delta Lake, including:
- Transactional consistency: Delta Lake provides a consistent view of data, even when multiple users or applications are writing to the same data at the same time. This is achieved through a distributed log that tracks all changes to data and ensures that all writes are applied atomically and in the correct order.
- Scalable performance: Delta Lake can handle petabytes of data and millions of reads and writes per second. It is designed to be highly scalable and can be easily integrated with existing data processing frameworks like Spark, Flink, and Presto.
- Unified access: Delta Lake provides a unified access layer for data stored in data lakes. This means that users can use any supported data processing framework to read, write, and analyze data in Delta Lake without having to worry about the underlying storage layer.
Overall, Delta Lake is a promising new storage layer for data lakes that offers significant advantages over traditional data lake storage options. It provides transactional consistency, scalable performance, and unified access, making it an ideal choice for organizations that need to store and process large amounts of data.
Components and Features of Delta Lake
Discovering the true power of Delta Lake requires understanding its important building blocks: Delta Storage, Delta Sharing, and Delta Connectors. These components work together to enhance the capabilities of Delta Lake and make data management, secure sharing, and integration with different big data engines effortless. Let’s explore each of these components in simpler terms to grasp their significance within the architecture of Delta Lake.
Delta Lake Storage
Delta Lake is a storage format that works on top of cloud-based data lakes. It brings transactional capabilities to data lake files and tables, essentially adding data warehouse-like features to a regular data lake. This storage format is the core component of the ecosystem, as all other parts depend on it for their smooth functioning and to unlock advanced functionalities.
Delta Sharing
Data sharing is when different companies need to exchange information securely. For example, let’s say a retail company wants to share its sales data with a logistics provider. By sharing this data, the logistics provider can better plan deliveries and manage inventory. In the past, setting up a secure data-sharing system like this was difficult and expensive.
That’s where Delta Sharing comes in. It’s a special way of securely sharing large amounts of data stored in a specific format called Delta Lake. With Delta Sharing, the retail company can securely share its sales data, which is stored in places like Amazon S3 or ADLS (Azure Data Lake Storage), with the logistics provider. Both companies can then access and use that shared data with their preferred tools, like Apache Spark or Power BI, without needing any extra setup. Plus, Delta Sharing even allows sharing data between different cloud providers without needing custom development.
In this case:
- The logistics provider can use Apache Spark to work with the shared sales data stored in Amazon S3 on their cloud platform.
- The retail company can use Power BI to directly analyze and visualize the shared sales data stored in ADLS.
In summary, Delta Sharing makes it easier for companies to securely share data, collaborate, and make better decisions, without the complexity and cost of building custom solutions.
Delta Connectors
The goal of Delta Connectors is to make Delta Lake accessible to other big data engines beyond Apache Spark. These connectors are open-source and enable direct connectivity to Delta Lake. One essential component is Delta Standalone, a Java library that allows reading and writing of Delta Lake tables without the need for an Apache Spark cluster. Applications can use Delta Standalone to connect directly to Delta tables created by their own big data infrastructure, eliminating the need for duplicating data in another format before consumption.
There are also native libraries available for different engines:
- Hive Connector: Reads Delta tables directly from Apache Hive.
- Flink/Delta Connector: Reads and writes Delta tables from Apache Flink applications. It includes a sink for writing to Delta tables and a source for reading Delta tables using Flink.
- SQL-delta-import: Allows importing data from a JDBC data source directly into a Delta table.
- Power BI Connector: A custom Power Query function that enables Power BI to read a Delta table from any file-based data source supported by Microsoft Power BI.
The Delta Connectors ecosystem is expanding rapidly, with new connectors being added regularly. An example is the recently introduced Delta Kernel in the Delta Lake 3.0 release. Delta Kernel and its simplified libraries remove the need to understand the technical details of the Delta protocol, making it easier to build and maintain connectors.
Conclusion
We have covered several important topics related to data management and the innovative framework known as Delta Lake. We began by understanding the concept of a data warehouse, which serves as a central repository for structured and organized data, enabling efficient analysis and reporting.
Next, we explored the concept of ACID transactions, which ensure the reliability and consistency of data operations within a database. These transactions guarantee that changes to the data occur reliably and as intended, even in the face of failures or concurrent access.
Moving on, we delved into the concept of a data lake, a flexible storage system capable of storing vast amounts of structured and unstructured data. Data lakes provide a cost-effective solution for storing and processing data, offering scalability and the ability to handle diverse data types.
Within the realm of data lakes, we encountered the innovative Delta Lake framework. Delta Lake combines the best features of data warehouses and data lakes, providing ACID transactions, schema enforcement, and optimized performance. This integration empowers organizations to leverage the reliability and efficiency of a data warehouse while benefiting from the flexibility and scalability of a data lake.
We explored the components and features of Delta Lake, including Delta Storage, which serves as the core storage layer of Delta Lake, providing reliability, transactional capabilities, and optimized performance. Delta Sharing, an open-source protocol, enables secure sharing of large datasets stored in Delta Lake across different cloud storage systems, facilitating seamless collaboration. Lastly, Delta Connectors expand the reach of Delta Lake beyond Apache Spark, allowing integration with other big data engines, such as Hive, Flink, SQL-based import, and Power BI.
By understanding these concepts and utilizing the components and features of Delta Lake, organizations can establish a robust data management framework that combines the best of data warehousing and data lakes, enabling efficient data processing, reliable sharing, and seamless integration across various data platforms.
Read more about the difference between Data Lake and Delta Lake here.